
엑셀과 ChatGPT 의 연결 생각해 보았나요? 그 첫번째는 "나의 필요를 AI 에게 어떻게 부탁할까?" 입니다. 프롬프트라고 하는 이 채팅 문장 작성, 인기를 얻고 있는 엑셀 프롬프트 7가지를 하나씩 함께해 봅니다.
📌 엑셀 작업을 10배 빠르게! ChatGPT 프롬프트 모음집으로 시간 절약하세요
이전 게시물 "엑셀+ChatGPT 프롬프트 2.데이터전처리1" 를 이어갑니다.
🧹 2. 데이터 전처리 프롬프트 - 지저분한 데이터도 깔끔하게 정리하기
프롬프트 템플릿 :
"[특정 문제] 같은 이슈가 있는 지저분한 데이터셋을 정리하는 단계별 과정 알려줘. 쓸만한 엑셀 함수랑 단축키도 같이 알려줘."
사용 예시 2: 불일치 텍스트 데이터 정리
프롬프트:
"제품명이 대소문자와 철자가 불일치하고, 제품 코드에 불필요한 접두어가 붙어있으며, 가격 데이터에 통화 기호와 천단위 구분기호가 섞여있는 데이터셋을 정리하는 단계별 과정 알려줘. 쓸만한 엑셀 함수랑 단축키도 같이 알려줘."
단계별 전처리 과정:
A. 제품명 대소문자 및 철자 통일
1> =PROPER(A2) 함수로 각 단어의 첫 글자만 대문자로 변환
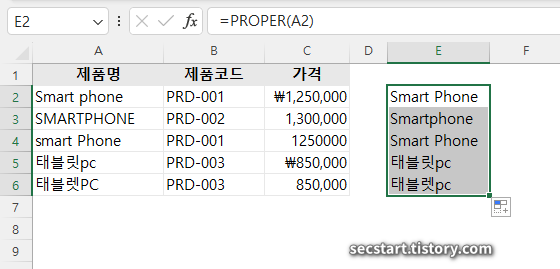
2> 특정 단어 일괄 변경: Ctrl + H로 찾기 및 바꾸기 대화상자 열기
3> 데이터 일관성 확보: 데이터 유효성 검사(Alt + D + L)로 드롭다운 목록 적용

B. 제품 코드 정리
1> =RIGHT(B2, LEN(B2)-4) 함수로 앞 3자리와 '-' 접두어 제거

2> 또는 =SUBSTITUTE(B2, "PRD-", "") 함수로 특정 접두어 제거
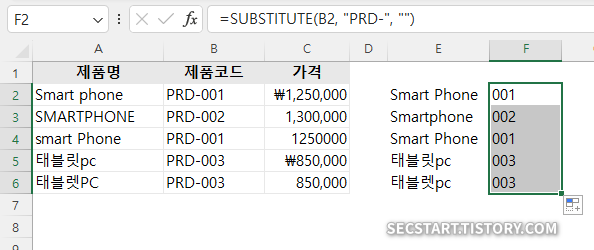
C. 가격 데이터 정리
1> 통화 기호 제거: =SUBSTITUTE(C2, "₩", "") // 텍스트 왼쪽 정렬

2> 천단위 구분기호 제거: =SUBSTITUTE(C2, ",", "") // 이함수의 결과는 텍스트형
3> 숫자로 변환: =VALUE(정리된_텍스트_셀) //숫자 오른쪽 정렬

4> 이상의 여러 작업을 한번에: =VALUE(SUBSTITUTE(SUBSTITUTE(C2, "₩", ""), ",", ""))
D. 데이터 형식 일관성 확보
1> 제품명: 텍스트 형식 지정
2> 제품 코드: 텍스트 형식 지정 (숫자 앞 0 유지)
3> 가격: 숫자 형식 지정 (통화 형식 Ctrl + Shift + $)

E. 정리된 데이터를 테이블로 변환
1> 데이터 범위 선택 후 Ctrl + T로 테이블 변환
2> 필터 및 정렬 기능 활용: 머리글 행의 드롭다운 메뉴
예제 데이터:
제품명,제품코드,가격
Smart phone,PRD-001,₩1,250,000
SMARTPHONE,PRD-002,"1,300,000"
smart Phone,PRD-001,1250000
태블릿pc,PRD-003,₩850,000
태블렛PC,PRD-003,"850,000"
사용 예시 3: 결측값 및 이상값 처리
프롬프트:
"설문조사 데이터에서 결측값과 이상값이 있는 데이터셋을 정리하는 단계별 과정 알려줘. 설문 문항에 따라 응답이 1-5 척도인데 범위를 벗어난 값이 있고, 일부 응답자 정보가 누락되어 있는 상황이야. 쓸만한 엑셀 함수랑 단축키도 같이 알려줘."
단계별 전처리 과정:
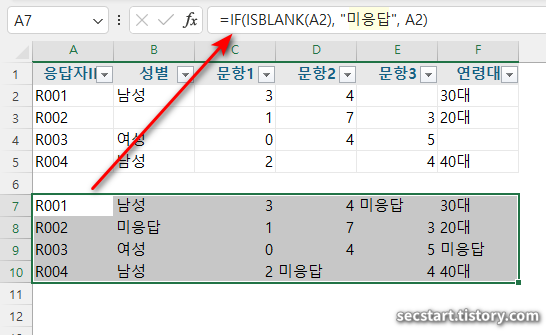
A. 결측값 식별 및 처리 // 아래는 단계가 아니에요, 여러 상황과 대처법입니다.
1> 결측값 찾기: Ctrl + F로 찾기 대화상자 열기, 빈 셀 찾기

2> 결측값 표시: =IF(ISBLANK(A2), "미응답", A2) 함수 사용
B. 이상값 식별 및 처리
1> 이상값 찾기: =IF(OR(C2<1, C2>5), "이상값", "정상") 함수로 범위 벗어난 값 표시

2> 조건부 서식 활용: 홈 탭 → 조건부 서식 → 규칙 관리 → 셀 값이 1-5 범위 밖인 경우 강조

3> 이상값 제거: =IF(AND(C2>=1, C2<=5), C2, NA()) 함수로 이상값을 #N/A로 처리
C. 데이터 일관성 확보
D. 처리된 데이터 요약 및 검증
- 기술통계 확인:
=AVERAGE(C:C),=STDEV(C:C),=MIN(C:C),=MAX(C:C)등 - 결측값 비율 계산:
=COUNTBLANK(C:C)/COUNTA(C:C) - 피벗 테이블 활용:
Alt + N + V로 피벗 테이블 생성, 데이터 패턴 검토
이상은 AI의 프롬프트에 대한 답변이에요. 이렇게 활용할 수 있다는 것을 배워요.
예제 데이터:
응답자ID,성별,문항1,문항2,문항3,연령대
R001,남성,3,4,,30대
R002,,1,7,3,20대
R003,여성,0,4,5,
R004,남성,2,,4,40대
사용 예시 4: 텍스트 데이터 분할 및 결합
프롬프트:
"고객 주소 데이터가 한 셀에 전체 주소가 들어있고, 이름 데이터는 성과 이름이 따로 분리되어 있는 데이터셋을 정리하는 단계별 과정 알려줘. 주소는 시/도, 시/군/구, 상세주소로 분리하고, 이름은 하나로 결합해야 해. 쓸만한 엑셀 함수랑 단축키도 같이 알려줘."
단계별 전처리 과정:
A. 주소 데이터 분할
1> 텍스트 나누기 기능: 데이터 선택 → 데이터 탭 → 텍스트 나누기 (Alt + A + E)
2> 구분 기호 기준 분할: 공백이나 쉼표 등 선택 (덱스트 나누기 마법사 3단계 에서 위치 지정)

3> 함수 사용 분할:
ㄱ. 시/도 추출: =LEFT(A2, FIND(" ", A2)-1)
ㄴ. 시/군/구 추출: =MID(A2, FIND(" ", A2)+1, FIND(" ", A2, FIND(" ", A2)+1)-FIND(" ", A2)-1)
ㄷ. 상세주소 추출: =RIGHT(A2, LEN(A2)-FIND(" ", A2, FIND(" ", A2)+1))
B. 이름 데이터 결합
1> 간단한 결합: =B2&" "&C2 (성과 이름 사이에 공백 추가)

2> AI가 알려준 두번째 결합범,,, CONCAT 함수 사용: =CONCAT(B2, " ", C2)
3> AI가 알려준 세번째 결합법,,, TEXTJOIN 함수 사용: =TEXTJOIN(" ", TRUE, B2, C2)
데이터 유효성 검사
- 주소 형식 검증:
=IF(COUNTIF(G2, "*시*")+COUNTIF(G2, "*도*")>0, "유효", "오류") - 이름 형식 검증:
=IF(AND(LEN(H2)>1, ISERROR(VALUE(H2))), "유효", "오류")
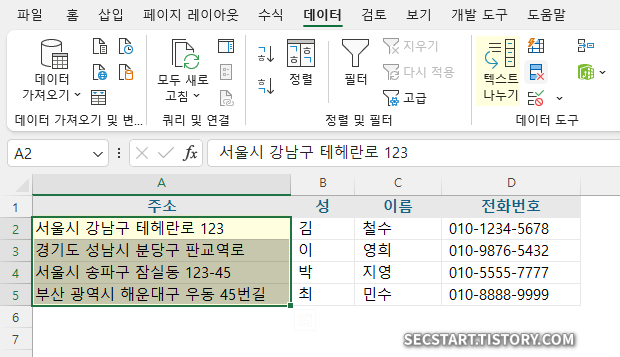
예제 데이터:
주소,성,이름,전화번호
서울시 강남구 테헤란로 123, 김, 철수, 010-1234-5678
경기도 성남시 분당구 판교역로, 이, 영희, 010-9876-5432
서울시 송파구 잠실동 123-45, 박, 지영, 010-5555-7777
부산 광역시 해운대구 우동 45번길, 최, 민수, 010-8888-9999
데이터 전처리 시 발생하는 주요 오류 정리
- #VALUE! - 데이터 유형 불일치 : TRIM, CLEAN 함수로 숨겨진 특수문자 제거, VALUE 함수로 텍스트를 숫자로 변환
- #REF! - 잘못된 참조 : 원본 데이터 위치를 확인하고 참조 수정, 삭제된 셀을 참조하지 않도록 주의
- #NAME? - 잘못된 함수명 또는 범위명 : 함수 이름의 철자 확인, 버전별 함수 지원 여부 확인 (TEXTJOIN, UNIQUE 등)
- #DIV/0! - 0으로 나누기 : IF 함수로 분모가 0인 경우 처리 (예:
=IF(B2=0, 0, A2/B2)) - #N/A - 값을 찾을 수 없음 : IFERROR 또는 IFNA 함수로 오류 메시지 대체 (예:
=IFERROR(VLOOKUP(...), "Not Found"))
데이터 전처리는 데이터 분석의 기초가 되는 중요한 작업이에요. ChatGPT의 도움을 받아 다양한 데이터 문제를 체계적으로 해결하면, 분석 품질도 향상되고 작업 시간도 크게 단축될 수 있어요!
위 예제들을 참고하여 자신의 데이터 특성에 맞는 전처리 전략을 수립하고, 엑셀의 다양한 기능과 함수를 활용해 보세요. 처음에는 복잡해 보여도 반복하면서 익숙해지면 쉬워질 거예요! 😊



